안녕하세요. 톡발이입니다.
오늘 지난 글에 이어서 계속 실습을 진행해보려고 합니다. 지난 글에서 wafer map dataset을 생성하는 것까지 완료했는데요. 오늘은 이렇게 만들어진 dataset을 가지고 CNN 모델을 직접 설계해서 분류해 보는 실습을 진행해 보겠습니다.
2023.10.18 - [분류 전체 보기] - Wafer Map Defect Pattern Classification Using CNN 실습 (1)
Wafer Map Defect Pattern Classification Using CNN 실습 (1)
안녕하세요. 톡발이입니다! 오늘은 제가 지난 글에서 리뷰한 CNN을 활용해 wafer map의 이상을 감지하고 분류하는 논문의 방법대로 실제로 dataset도 생성해 보고 CNN을 이용해 분류해 보는 실습을 진
aiegg-travel.tistory.com
먼저 dataset을 각각 train set, validation set, test set으로 나누어줘야겠죠? 저는 논문에서와 같이 각각을 700장, 300장, 300장으로 나누어 보겠습니다.
Train Test Split
먼저 필요한 모듈과 변수들을 import 합니다.
import os
import glob
import random
import shutil
from sklearn.model_selection import train_test_split# train, val, test 이미지 개수
num_train_images = 700
num_val_test_images = 300
이제 train set, validataion set, test set을 저장할 디렉터리를 생성해줍니다.
for i in range(1, 23):
os.mkdir(f"/content/drive/MyDrive/data/train_set/C{i}")
os.mkdir(f"/content/drive/MyDrive/data/val_set/C{i}")
os.mkdir(f"/content/drive/MyDrive/data/test_set/C{i}")
이렇게 생성된 디렉터리에 wafer map 이미지를 랜덤 하게 뽑아서 train, validation, test set으로 정해진 수만큼 나눠보겠습니다.
# train, val, test 이미지 무작위로 선택하여 분할
for class_num in range(1, 23):
train_files = []
val_files = []
test_files = []
# wafer map 이미지가 저장되어 있는 곳
class_files = glob.glob(f"/content/drive/MyDrive/wafer_map/C{class_num}/*")
# 이미지들을 랜덤하게 섞어줍니다
random.shuffle(class_files)
train_images = class_files[:num_train_images]
val_test_images = class_files[num_train_images:]
train_files.extend(train_images)
# val, test 이미지를 무작위로 선택하여 분할
val_images, test_images = train_test_split(val_test_images, test_size=num_val_test_images, random_state=42)
val_files.extend(val_images)
test_files.extend(test_images)
# 이미지 파일 복사
for file in train_files:
shutil.copy2(file, f"/content/drive/MyDrive/data/train_set/C{class_num}")
for file in val_files:
shutil.copy2(file, f"/content/drive/MyDrive/data/val_set/C{class_num}")
for file in test_files:
shutil.copy2(file, f"/content/drive/MyDrive/data/test_set/C{class_num}")Data Loader
이제 train, validation, test set이 준비가 되었으니 이들을 CNN 모델에 훈련시킬 수 있도록 data loader를 생성해야 합니다.
먼저 필요한 모듈을 불러와줍니다.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
Data Loader를 생성해 봅시다.
# 데이터셋 폴더 경로
data_dir = "/content/drive/MyDrive/data"
train_dir = os.path.join(data_dir, "train_set")
val_dir = os.path.join(data_dir, "val_set")
test_dir = os.path.join(data_dir, "test_set")
# 이미지 크기
image_size = (286, 400)
# 데이터 전처리 변환
data_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor()
])
# 데이터셋 로드
train_dataset = ImageFolder(train_dir, transform=data_transform)
val_dataset = ImageFolder(val_dir, transform=data_transform)
test_dataset = ImageFolder(test_dir, transform=data_transform)
# 데이터 로더 생성
batch_size = 110
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)논문에서는 모델의 입력 이미지 사이즈를 (286, 400)으로 해주었기 때문에 저도 같은 크기로 Resize 시켜주었습니다. Batch size 같은 경우 colab의 메모리 사용량에 한계가 있어서 적당히 110으로 설정해 주었습니다.
(사실 학교에서 제공해 주는 좋은 서버와 GPU가 있지만 이 때는 아직 서버나 도커 등에 대한 지식이 없어서 colab으로 실험을 했습니다.)
참고로 저 같은 경우에는 실험 도중 gpu 메모리 오류가 가끔씩 떴는데 그럴 때마다 아래의 코드를 실행시켜 주면 해결될 때가 있었습니다.
# gpu 메모리 오류날 때 한번 써보자
import gc
gc.collect()
torch.cuda.empty_cache()
Train loader에서 데이터를 잘 가져와 주는지 확인해 봅시다.
# train_loader에서 배치 가져오기
batch = next(iter(train_loader))
# train_dataset에서 클래스 이름 목록 가져오기
class_names = train_dataset.classes
# 배치에서 첫 번째 이미지와 레이블 가져오기
image = batch[0][0] # 첫 번째 이미지
label_index = batch[1][0].item() # 첫 번째 이미지의 레이블 인덱스
# 클래스 이름으로 레이블 표시
label = class_names[label_index]
# 이미지 확인
plt.imshow(image.permute(1, 2, 0))
plt.title(f"Label: {label}")
plt.axis('off')
plt.show()
잘 가져와지는 것 같네요.
Model
모델은 CNN을 사용하겠습니다. 또한 Architecture는 논문에서 사용한 것을 그대로 구현을 해보려고 합니다. 혹시 기억이 안나시는 분들은 아래 글을 참고해 주세요!
2023.10.17 - [분류 전체 보기] - CNN으로 Wafer Map Defect Pattern 분류하기 (논문 리뷰)
CNN으로 Wafer Map Defect Pattern 분류하기 (논문 리뷰)
안녕하세요. 이 글에서는 CNN으로 Wafer Map Defect Pattern을 분류하는 방법을 제안하는 논문을 하나 리뷰해 보려고 합니다. "Wafer Map Defect Pattern Classification and Image Retrieval Using Convolution Neural Network"이라
aiegg-travel.tistory.com
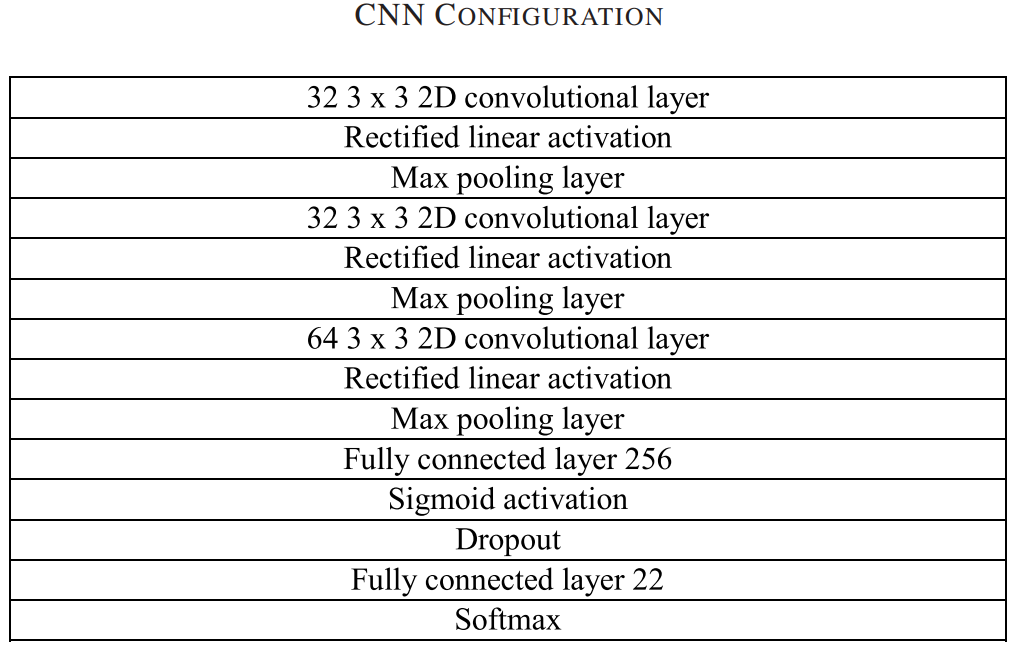
class MyModel(nn.Module):
def __init__(self, num_classes=22):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=0)
self.conv2 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=0)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=0)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(104448, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = self.maxpool(self.relu(self.conv3(x)))
x = x.view(x.size(0), -1)
x = self.sigmoid(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return xforward 부분에서 첫 번째 layer를 지나면 (284, 400) 사이즈였던 이미지가 Conv1을 지나서 (284, 398) 사이즈가 되고 Max Pooling으로 (142, 199) 사이즈가 됩니다.
이런 식으로 두 번째의 layer의 output 사이즈는 (70, 98)이 되고 마지막 Conv3 layer의 최종 output 사이즈는 (34, 48)이 됩니다. 이때 channel의 수는 64이므로 34 x 48 x 64 = 104448이 되고 이 값이 첫 번째 FC layer의 input 값이 됩니다.
물론 이렇게 일일이 구하지 않고 x.view(x.size(0), -1)에서 사이즈를 쉽게 구할 수 있습니다.
Loss와 optimizer는 논문과 같이 CE Loss와 Adam을 사용했습니다.
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 인스턴스 생성
model = MyModel().to(deivce)Train
# 모델 학습 경로
checkpoint_path = "/content/drive/MyDrive/model_checkpoint.pt"
train_acc_list = [] # train accuracy를 저장할 리스트
val_acc_list = [] # validation accuracy를 저장할 리스트
for epoch in range(10):
model.train()
train_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_loss /= len(train_loader)
train_acc = 100.0 * correct / total
train_acc_list.append(train_acc) # train_acc를 리스트에 추가
# 검증 데이터 평가
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
val_loss /= len(val_loader)
val_acc = 100.0 * correct / total
val_acc_list.append(val_acc) # val_acc를 리스트에 추가
print(f"Epoch {epoch+1}: Train Loss: {train_loss:.4f}, Train Accuracy: {train_acc:.2f}%, Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_acc:.2f}%")
# 모델 파라미터 저장
torch.save(model.state_dict(), checkpoint_path)
훈련이 끝나고 그래프로 성능을 확인해 보았습니다.
# Epoch 수를 x축으로 사용합니다.
epochs = range(1, len(train_accuracy) + 1)
# Train accuracy와 validation accuracy를 그래프로 그립니다.
plt.plot(epochs, train_acc_list, 'bo--', label='Train')
plt.plot(epochs, validation_acc_list, 'r^-', label='Validation')
plt.xlabel('Epoch')
plt.ylabel('Accuracy[%]')
plt.legend()
plt.grid(axis='y')
plt.show()
논문과 얼추 비슷한 형태의 그래프가 나온 것 같죠?
Test
이제 훈련된 모델을 사용해 최종 test를 해보겠습니다.
# 저장된 모델 파라미터 불러오기
model.load_state_dict(torch.load("/content/drive/MyDrive/model_checkpoint.pt"))
# Inference
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
test_acc = 100.0 * correct / total
print(f"Test Accuracy: {test_acc:.2f}%")최종 Test Acuuracy 결과는 98.29%가 나왔습니다.
이렇게 해서 논문의 실습은 모두 끝났습니다. 생각보다 성능이 매우 잘 나와서 기분이 좋네요. 하지만 CNN 모델인 만큼 parameter 수도 많고 그만큼 연산량이 많아서 그런지 10 epochs 밖에 안되는데도 시간이 엄청나게 오래 걸렸습니다.
긴 글 읽어주셔서 감사합니다!